
https://arxiv.org/abs/1912.09637
Introduction
大量のテキストで事前学習をする言語モデルは2019年時点で性能がすごく良い。既存のものは入力されたテキストだけではなく、ちゃんと外部の知識も使って答えるようにしている。
既存の事前学習目標はTokenレベルで定義され、実態中心の知識を明示的にモデル化していない。この研究では実態に焦点を当てている。
実態知識が必要な2つの典型的なタスクを解く。Question Answeringとfine-grained Entity Typing(短い文脈で指定された何か(人名、地名などのentity)が何のカテゴリーやタイプに属しているか(職業、都市etc))をこたえること。弱教師付き学習でうまくいったのよね。
この論文では、以下のことが達成できた。
- 既存の事実完成評価(Fact Completion Evaluation 一部欠けている情報を持つテキストから、どれほど正確な事実や知識を抽出、再構成できたかの評価)を拡張して、事前に訓練されたモデルが一般的な実世界の実態にかかわる知識を学べるように。
- 新しい弱教師学習による事前学習手法をを提案。より実際のentityをとらえられるように。
- QAとfine-grained Entity-Typingでより良い性能が出せた。
Entity Replacement Training
弱教師学習の知識を使った、Entity中心の学習を考える。入力としてドキュメントを与えると、それをWikipediaのEntityと結びつける。(気持ちでいうと、Wikipediaのリンクがあって、ページがあるものがEntityという認識でいいです Wikipediaは絶対に正しいという想定でやっている)
- オリジナルのテキストはPositive
- そのオリジナルから、ランダムに一部のEntityに置き換える (「元王朝の初代皇帝は、フビライ・ハーン → チンギス・ハーン(嘘のEntityにした)である。」) これをNegativeとする。同じ人物なら人物、都市名なら都市名と置き換える形。
そして、文章 に含まれている Entity が置き換えられたかどうかの識別器を訓練する。
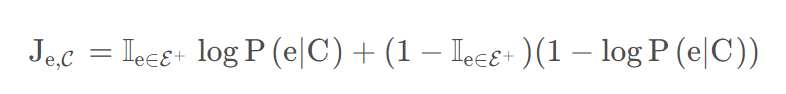
ロスは、 が正しい( )のならば、 の損失を与える(Cという文章、文脈であるときに が生成される確率に急激な変化をとらえさせないようにlogをとったもの。)、というようなもの。これ最大化させたいの?
Entityがこの文章、文脈で正しいなら、含まれる確率が大きく、logをとってもかわらない。正しくないなら、1-logでも同様だ。
Data Preparation
Wikipediaを使う。リンクをEntityとする。トークンの長さは512で切る。Wikipediaを使っているがWikipediaというコーパスで必ずやらないといけない理由はない。
Replacement Strategy
置換をするとき、隣接するEntityを両方とも置換することは禁止する。偶然どちらも置換した結果正解が偶然できてしまうのを防いでいる。
Model
BERT-baseのモデルを使う。12層のTransformerで隠れ層が768次元であることの構造のままを使う。最終層で0.05の確率で頂点をドロップアウトする。
Training Objectives
Masked Language Modelによる事前学習は下流タスクの処理に有用である。ただし、Entityの上にMaskを掛けることは禁止する。Masking Ratioも15%から5%nに下げている。128のバッチサイズで1M回の事前学習を行った。